MoE
MoE
基本原理
MoE,全称 Mixture of Experts,混合专家模型。
- 传统的 Dense 模型:每个输入 token 都需要经过模型的所有参数。参数越多,计算量越大。
- MoE 的思路:将模型的某些层拆成多个专家网络。专家前面加上门控网络(Router),负责决定每个 token 应该被送到哪几个专家那里处理。
这样设计 / 做的好处包括:
- 计算效率高:模型总参数量很大,但每次推理只用一部分,实际参与计算的参数量很小(稀疏激活),计算量大大减少。
- 理论上限更高:因为总参数可以做的很大,理论上模型能学到更多的知识,能力上限更高。
- 训练成本更低:用更少的计算成本可以训练出更大容量的模型。
典型的做法为将 transformer 中的 FNN 拆成多个专家:
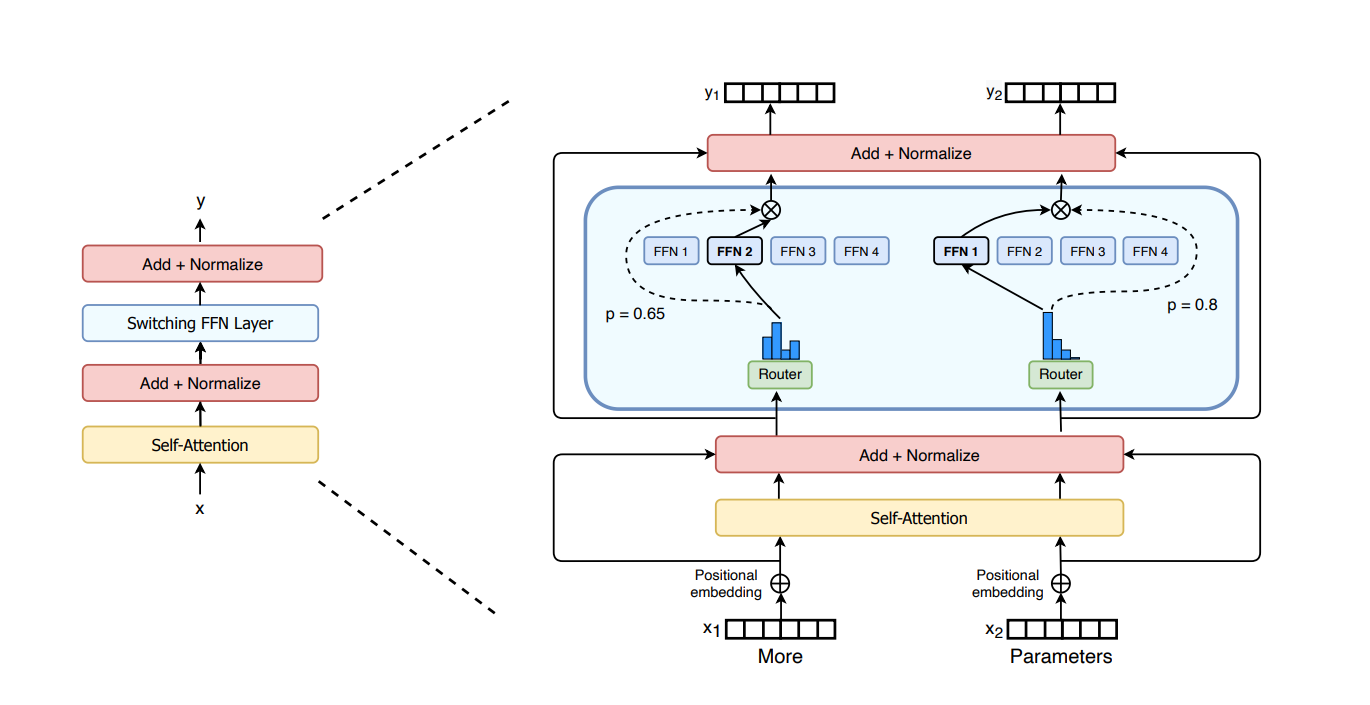
问题
负载不均衡
门控网络分配 token 时可能出现严重的不均衡,某些专家一直被激活,token 排队等待处理;某些专家没有被分配 token,门可罗雀。
这会导致两个严重的问题:
- 专家塌陷:被激活过少的专家训练不充分,参数几乎没有更新过,占用了显存却没有贡献任何能力。
- 容量瓶颈:受限于硬件资源限制,每个专家能够处理的 token 数量是有上限的。如果超出了上限,token 会被丢掉,造成信息损失。
主流的解决方案分两种:
辅助损失,Auxiliary Loss
这是最传统、最广泛使用的方案。思路为:在训练的损失函数中增加对负载不均衡的惩罚项,强迫模型学习均匀分配。
方法很直观,但实际使用时需要考虑辅助损失的权重怎么设置。设得太小,损失不起作用,负载依然不均衡;设得太大,模型被迫将 token 均匀分配,但这可能不是最优的分配方式。某些 token 就是需要特定专家处理,强行分配给别人会损害模型效果。
最终只能在模型效果和负载均衡间做 trade-off,不断尝试,找到特定数据集、特定模型规模下的可接受的参数设置。
无辅助损失,Auxiliary Loss Free
DeepSeek 在 V2 里提出一个解决方案:不改动损失函数,在门控网络的输出上给每个专家加一个可学习的偏置。如果被分配的 token 太少,就提高对应专家的偏置。
这样既不干扰主损失函数,从而不损害模型效果,又能实现负载均衡。
但在实现上,这样做更复杂,需要额外的工程工作,某些场景下也不一定比调得好的辅助损失解决方案效果更好。
推理阶段的挑战
显存问题
虽然一次推理只激活部分专家,但必须提前准备好所有专家,因此需要将整个模型加载到显存里。这使得 MoE 架构的模型虽然推理速度相比于同等计算量的 Dense 模型更快,但对显存的要求却比同等计算量的 Dense 模型大得多。
通信问题
当模型规模大到一定程度时,势必要使用分布式部署。
通常的做法是:不同的专家放在不同的 GPU 上。门控网络决定 token 需要给哪个专家处理后需要将它发送到对应的 GPU 上处理,处理完再发送回来。这个过程涉及大量的跨 GPU、甚至跨机器的通信,带来很大的通信开销,减弱 MoE 架构带来的推理速度上的优势。
专家不专
理想情况下,MoE 模型应当按照设计初衷不同的专家各有所长,分别负责处理不同类型的输入,最终整个模型就像一个团队,各司其职,协同工作。但,实际情况比较复杂。
在编码器中,专家表现出一定程度的专业化,可以明显看到不同类型的 token 输入时专家的激活模式差异。但在解码器中,很多专家的功能是重叠的,很难说清楚某个专家到底专在哪里。
多余专家
不管怎么训练,总有一些专家的激活频率特别低,使得模型的整体架构冗余。因此在实际部署中往往需要做专家剪枝,把不怎么激活的专家直接砍掉,减少显存占用和模型体积。
剪枝操作说起来容易,做起来难。剪掉哪些专家、剪多少、剪完之后需不需要微调都是实际工程中需要额外考虑的问题。
训练不稳定
门控网络的梯度
门控网络需要做一个离散的决策,但离散决策是不可导的,不能直接使用梯度下降优化。因此实际使用时都是一些近似方法,如用 Softmax 产生一个软分配,或者用 Gumbel-Softmax。但这些方法都各有问题,可能导致训练不稳定或收敛困难。
舍入误差
门控网络里通常会用到 Softmax,Softmax 中有指数运算,当值很大或很小的时候,容易产生舍入误差。这样的误差在 Dense 模型中不是什么大问题,但在 MoE 下可能会方法,导致训练出现 NaN 或 Inf。
所以,在做 MoE 训练时,通常需要特别注意数值稳定性,可能会用到一些特殊技巧,如在 Softmax 之前减去最大值,或者用混合精度训练的时候特别小心某些层的精度设置。
专家分配
在训练初期,门控网络没有学好,专家分配可能非常不稳定。一个 batch 的 token 都去了专家 A,下一个 batch 又全去了专家 B。这种不稳定会导致每个专家看到的数据分布剧烈波动,进而导致整个模型训练不稳定。
解决方法之一是:在训练初期使用更强的负载均衡约束,等模型稳定之后再逐渐放松。但具体如何设计这个逐渐放松的策略,完全是一个需要经验的地方。
适用范围
不适合小规模场景
如果数据量很小,模型规模本来就不大,使用 MoE 反而会导致过拟合,还会带来更高的工程复杂度,导致使用 MoE 带来的额外成本大于收益。
不适合对延迟极度敏感的场景
虽然 MoE 的计算量小,但通信开销大,显存要求高,在某些对延迟要求极高的场景,一个小而快的 Dense 模型要比一个大而复杂的 MoE 模型更合适。
不适合部署到资源受限的环境
如边缘设备、手机、或者显存很小的 GPU,MoE 对显存的要求会成为硬伤。
DeepSeek V2 的 MoE 创新
细粒度专家
传统的 MoE,如 Mixtral,用的是 8 个大专家,每个 token 选 2 个。
DeepSeek V2 用的是 160 个小专家,每个 token 选 6 个。
这样做的好处在于专家组合的可能性更多,这意味着模型可以为每个 token 找到更精确的专家组合,表达能力更强。
共享专家
DeepSeek 除了 160 个小专家,还设置了几个共享专家。这些共享专家对所有 token 都激活,不参与路由选择。
为什么这样做?因为有些知识是通用的,所有 token 都需要。如果把这些通用知识也交给路由选择,既浪费专家容量,又增加路由负担。不如直接设置几个共享专家,专门处理通用知识。
无辅助损失的负载均衡
传统的辅助损失方案有损害模型效果的风险。DeepSeek 用动态偏置的方案,在不损害效果的情况下实现了负载均衡。
面试
问:为什么现在主流大模型都用 MoE 而不是 Dense?
因为 MoE 是稀疏激活的,每个 token 只激活部分专家,计算量小,训练快,能用更少的算力训练更大的模型。
(MoE 的挑战)不过 MoE 也有它的问题。最核心的是负载均衡,很难保证每个专家被均匀地激活。如果负载不均衡,一些专家训练不充分,等于浪费了参数。另外推理的时候,虽然计算量小,但参数量大,显存要求高,分布式部署的通信开销也大。
(实际经验 / 最新进展)我之前看过 DeepSeek-V2 的技术报告,他们用的是细粒度专家加共享专家的设计,每个 token 选 6 个小专家加上几个共享专家。负载均衡用的是无辅助损失的方案,通过动态调整偏置来实现,避免了传统 auxloss 损害模型效果的问题。我觉得这个方向挺有意思的,把 MoE 的设计空间探索得更深了。
(实际做过 MoE 相关工作的经验,如训练、推理优化、专家剪枝等)我们之前在做某某项目的时候,也尝试过 MoE,当时主要的精力花在调负载均衡的 aux loss权重上。后来发现效果一般,就还是用了 Dense 模型。但那次经历让我对 MoE 的实际工程挑战有了更深的理解。
问:MoE 和 Dense,哪个效果更好?
这个不能一概而论。在相同的训练算力下,MoE通常能达到更好的效果,因为它的模型容量更大。但在相同的参数量下,Dense模型的参数利用效率更高。另外还要看具体的任务和数据,数据量太小的话,MoE可能反而过拟合。
问:Router 是怎么训练的?
Router 通常和整个模型一起端到端训练。它的输出是一个概率分布,表示每个专家被选中的概率。常见的做法是用 Top-K 选择,选概率最高的 K 个专家。反向传播的时候,通过被选中的专家的梯度来更新 Router 的参数。有些工作也探索过用强化学习来训练 Router,但端到端训练还是主流。
问:Expert Parallelism 是什么?
这是 MoE 模型常用的一种并行策略。把不同的专家放在不同的 GPU 上,每个 GPU 只负责计算自己的专家。token 通过 All-to-All 通信在不同 GPU 之间传递。这样做的好处是每个 GPU 的计算量更小,坏处是通信开销大。通常会和 Tensor Parallelism、 Pipeline Parallelism 结合使用。
问:怎么判断一个 MoE 模型训练得好不好?
除了看常规的 loss 和下游任务指标,还要看专家的利用率。如果有些专家几乎不被激活,说明负载均衡没做好,或者专家数量设计得不合理。还可以分析不同专家处理的 token 有没有什么 pattern,看专业化有没有形成。