LoRA / QLoRA
2026/4/17大约 3 分钟
LoRA / QLoRA
LoRA 属于 参数高效微调(PEFT,Parameter-Efficient Fine-Tuning)技术中的一种
QLoRA 是在 LoRA 的基础上,引入了极端的 量化(Quantization)技术
PEFT 技术的整体思想是冻结大模型的大部分参数,再引入一小部分可训练的参数作为适配模块进行微调训练,以达到节省大模型微调时显存开销的目的
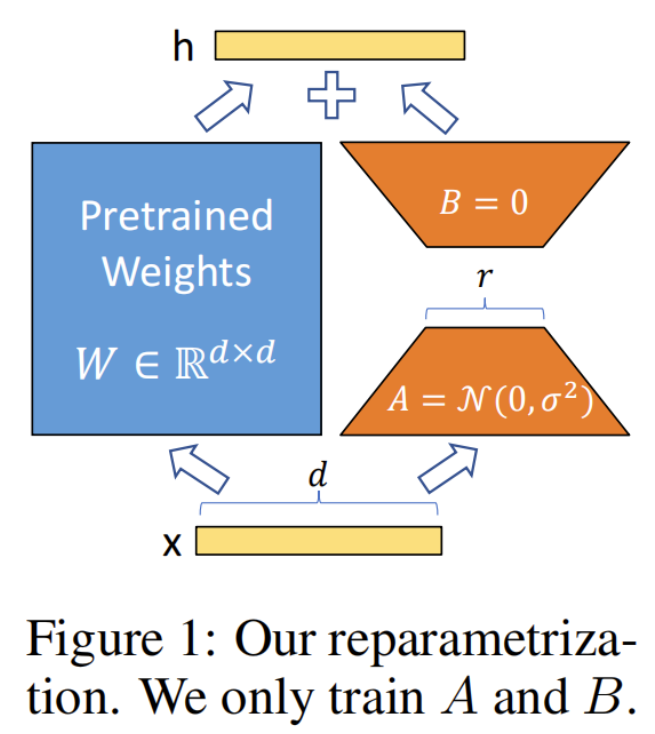
动机
深度网络由大量 Dense 层( nn.Linear(hidden_size, hidden_size )构成,这些参数矩阵通常是满秩的
LoRA 假设 LLM 在下游任务上微调得到的增量参数矩阵 是低秩的(肯定不是满秩),即存在冗余参数或高度相关的参数矩阵,但实际有效参数是更低维度的。
LoRA 实现
LoRA 在冻结原有 LLM 参数时,用参数量更小的矩阵进行低秩近似训练。
对于预训练权重矩阵 ,LoRA 限制了其更新方式,即将全参微调的增量参数矩阵表示为两个参数量更小的矩阵 和 的低秩近似:
矩阵 和 的秩 远小于 的维度
LoRA 后模型的输出为: ,记
LoRA 训练 时, 被冻结,不会计算其梯度
推理 时,直接按上面的式子将 合并到 中,因此相比原始 LLM 不存在推理延时
LoRA 初始化
开始训练时:
- 矩阵 为全零初始化
- 矩阵 通过高斯函数初始化
- 微调就能从预训练权重 开始
实际实现时, 会乘以系数 , 是一个超参
- 系数 越大,LoRA 微调权重的影响就越大,在下游任务上越容易过拟合
- 系数 越小,LoRA 微调权重的影响就越小(微调的效果不明显,原始模型参数受到的影响也较少)
一般来说,在给定任务上LoRA微调,让 为 的 2 倍
根据经验,LoRA 训练大概很难注入新的知识,更多是修改 LLM 的指令尊随的能力,例如输出风格和格式
LoRA 的秩如何选择
秩 r 选取经验:
- 简单任务所需的秩不大,任务越难、多任务混合的情况,需要更大的秩
- 越强的基座,所需的秩应该更小。例如 Qwen2-72B-Instruct 对比 Qwen2-7B-Instruct。越强的基座在处理同等任务时,需要微调的样本数也通常会更少些
- 数据规模越大或任务越难,越需要更大的秩
LoRA 放哪
LoRA 原始论文只研究了注意力参数
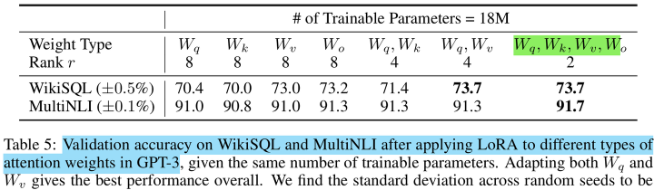
即使全部的注意力参数即使秩更小时 (),相比秩更大的部分注意力参数(),具有更强的建模能力。在实际中,一般会把 FFN 的参数也考虑进来