量化
量化
量化基础
大模型量化的核心在于将模型参数的精度从较高的位宽(bit-widths)(例如 32 位浮点数)降低到较低的位宽(例如 8 位整数)。
| 格式名称 | 总位数 | 结构 (指数/尾数) | 核心区别与应用场景 (新增列) |
|---|---|---|---|
| FP64 (双精度) | 64-bit | 11 / 52 | 科学计算标准。精度极高,但在深度学习中极少使用,因为太占显存且计算慢。 |
| FP32 (单精度) | 32-bit | 8 / 23 | 深度学习基准。所有权重的“黄金标准”,训练最稳定,但显存占用大。 |
| TF32 (TensorFloat) | 19-bit | 8 / 10 | NVIDIA Ampere 架构特有。它截断了 FP32 的尾数,保留了 FP32 的范围。在 A100/H100 上默认使用,是 FP32 的加速替代品。 |
| BF16 (Brain Float) | 16-bit | 8 / 7 | 大模型训练主流。牺牲精度换取范围。它的范围和 FP32 一样大,训练时不容易溢出,是目前 LLM 训练的首选。 |
| FP16 (半精度) | 16-bit | 5 / 10 | 传统混合精度/推理。精度比 BF16 高,但范围太窄(容易上溢/下溢),训练时通常需要“Loss Scaling”技巧。 |
| FP8 (E4M3/E5M2) | 8-bit | 4/3 或 5/2 | H100/H200 新宠。用于超大模型的高效推理和部分训练,速度极快,显存极省。 |
| INT8 (整型) | 8-bit | 无 (整数) | 推理量化标准。模型训练完后,将其“压缩”为整数进行推理(Quantization),速度最快 |
对称量化 Symmetric Quantization
对称量化:原本浮点数的值域会被映射到量化空间(quantized space)中一个以零为中心的对称区间,量化前后的值域都是围绕零点对称的。
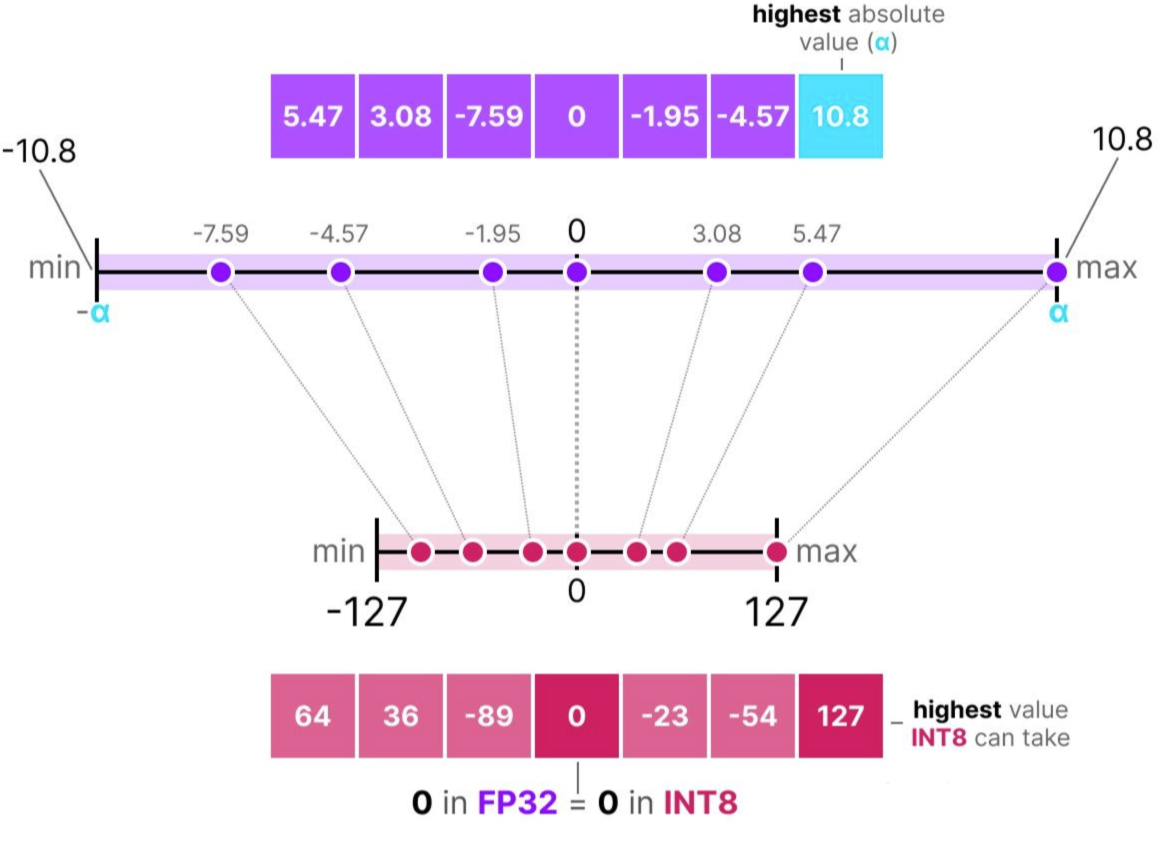
为了恢复原始的 FP32 值,我们可以使用之前计算出的比例因子(s)来对量化后的数值进行反量化(dequantize)
某些值(如 3.08 和 3.02 )在量化到 INT8 后,都被分配了相同的值 36。当这些值反量化(dequantize)回 FP32 时,会丢失一些精度,变得无法再区分
这种现象通常被称为量化误差(quantization error),我们可以通过比较原始值(original values)和反量化值(dequantized values)之间的差值来计算这个误差。
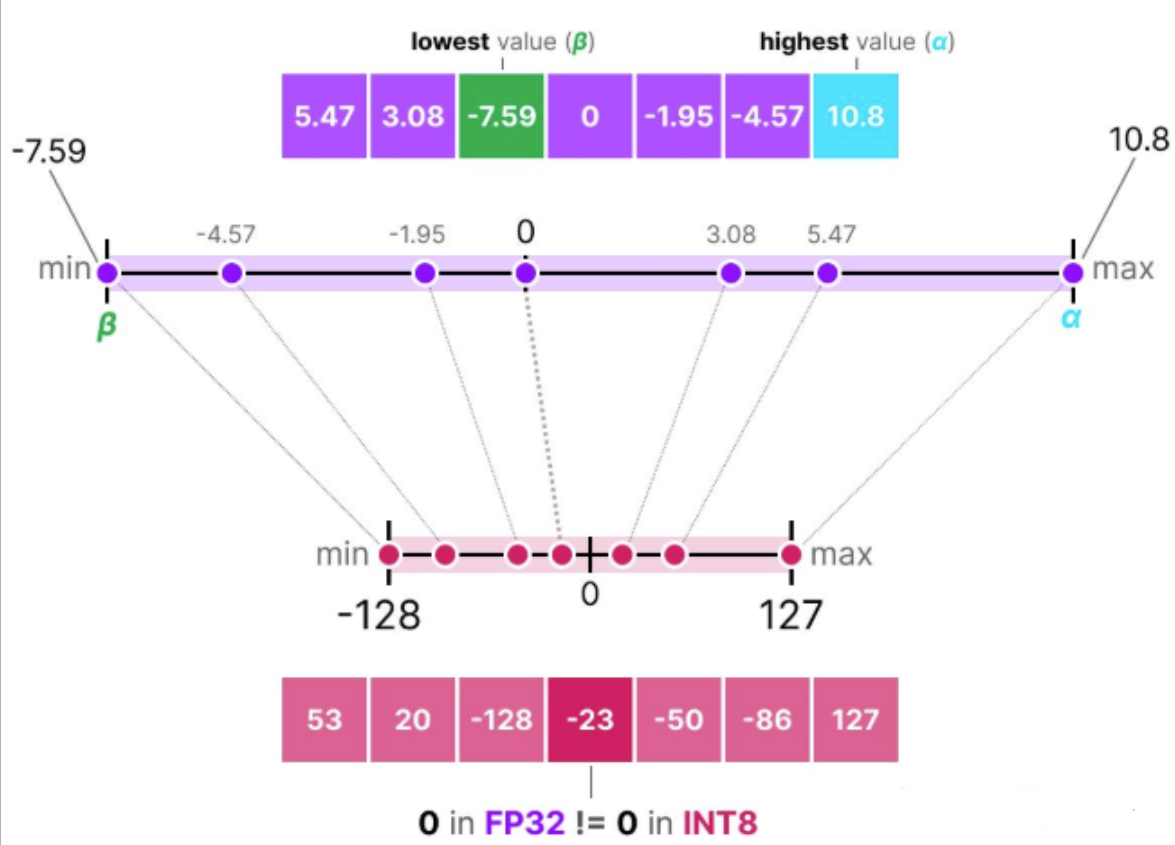
非对称量化 Asymmetric quantization
非对称量化并不是以零为中心对称的。它将浮点数范围中的最小值(β)和最大值(α)映射到量化范围(quantized range)的最小值和最大值。
GGUF 量化
GGUF 通常使用分组量化,比如将权重矩阵分成多个小块,使用对称量化或非对称量化对每个小块进行量化
W = [
[0.28, -1.32, 0.66, 2.10],
[0.91, -0.45, -0.72, 1.80],
[-0.34, 1.22, -0.89, -1.50],
[0.15, -0.60, 0.33, 0.92]
]
Group 1: [0.28, -1.32, 0.66, 2.10] # 第一行
Group 2: [0.91, -0.45, -0.72, 1.80] # 第二行
Group 3: [-0.34, 1.22, -0.89, -1.50] # 第三行
Group 4: [0.15, -0.60, 0.33, 0.92] # 第四行
# 对称量化 或 非对称量前面介绍的量化方法都是不考虑量化误差的,因此效果往往比较差。需要考虑量化误差,提升量化效果
PTQ
后训练量化(PTQ, Post-Training Quantization)一般是指在模型预训练完成后,基于校准数据集(calibration dataset)确定量化参数进而对模型进行量化。
GPTQ
GPTQ (Group-wise Precision Tuning Quantization) 是一种静态的后训练量化技术。「静态」指的是预训练模型一旦确定,经过量化后量化参数不再更改。GPTQ 量化技术将 fp16 精度的模型量化为 4-bit ,在节省了约 75% 的显存的同时大幅提高了推理速度。 为了使用 GPTQ 量化模型,您需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-GPTQ
QAT
在训练感知量化(QAT, Quantization-Aware Training)中,模型一般在预训练过程中被量化,然后又在训练数据上再次微调,得到最后的量化模型。
需要重新训练模型,计算成本极高,不适用于大规模LLMs
AWQ
AWQ(Activation-Aware Layer Quantization)是一种静态的后训练量化技术。其思想基于:有很小一部分的权重十分重要,为了保持性能这些权重不会被量化。 AWQ 的优势在于其需要的校准数据集更小,且在指令微调和多模态模型上表现良好。 为了使用 AWQ 量化模型,您需要指定量化模型名称或路径,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-AWQ
AQLM
AQLM(Additive Quantization of Language Models)作为一种只对模型权重进行量化的 PTQ 方法,在 2-bit 量化下达到了当时的最佳表现,并且在 3-bit 和 4-bit 量化下也展示了性能的提升。 尽管 AQLM 在模型推理速度方面的提升并不是最显著的,但其在 2-bit 量化下的优异表现意味着您可以以极低的显存占用来部署大模型。
OFTQ
OFTQ (On-the-fly Quantization) 指的是模型无需校准数据集,直接在推理阶段进行量化。OFTQ 是一种动态的后训练量化技术. OFTQ 在保持性能的同时。 因此,在使用 OFTQ 量化方法时,您需要指定预训练模型、指定量化方法 quantization_method 和指定量化位数 quantization_bit 下面提供了一个使用bitsandbytes量化方法的配置示例:
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
quantization_bit: 4
quantization_method: bitsandbytes # choices: [bitsandbytes (4/8), hqq (2/3/4/5/6/8), eetq (8)]bitsandbytes
区别于 GPTQ,bitsandbytes 是一种动态的后训练量化技术。bitsandbytes 使得大于 1B 的语言模型也能在 8-bit 量化后不过多地损失性能。 经过 bitsandbytes 8-bit 量化的模型能够在保持性能的情况下节省约 50% 的显存。
HQQ
依赖校准数据集的方法往往准确度较高,不依赖校准数据集的方法往往速度较快。HQQ(Half-Quadratic Quantization)希望能在准确度和速度之间取得较好的平衡。作为一种动态的后训练量化方法,HQQ 无需校准阶段, 但能够取得与需要校准数据集的方法相当的准确度,并且有着极快的推理速度。
EETQ
EETQ (Easy and Efficient Quantization for Transformers) 是一种只对模型权重进行量化的 PTQ 方法。具有较快的速度和简单易用的特性。