蒸馏
2026/4/17大约 1 分钟
蒸馏
Knowledge Distillation,简称 KD,顾名思义,就是将已经训练好的模型包含的知识「Knowledge」,蒸馏「Distill」提取到另一个模型里面去
大模型不方便部署到服务中去,常见的瓶颈有:
- 推断速度慢
- 对部署资源要求高(内存,显存等)
因此,模型压缩(在保证性能的前提下减少模型的参数量)成为了一个重要的问题。而 模型蒸馏 属于模型压缩的一种方法
知识蒸馏的具体方法
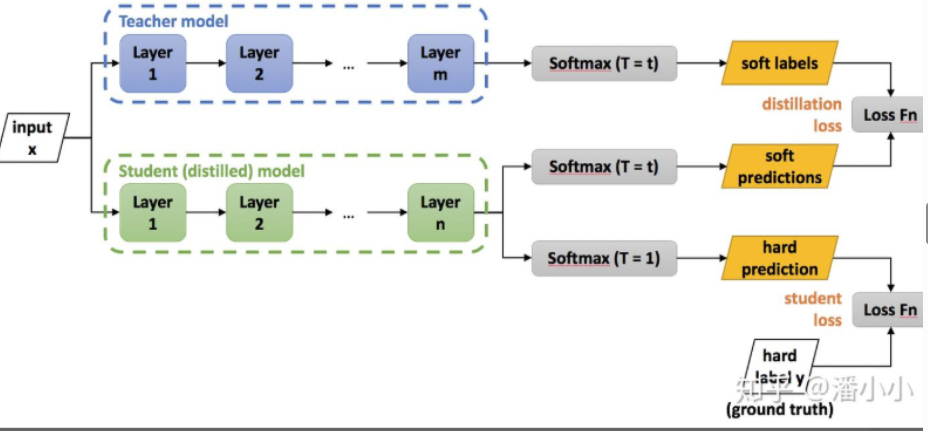
在知识蒸馏时,我们已经有了一个泛化能力较强的 Net-T(教师模型),我们在利用 Net-T 来蒸馏训练 Net-S(学生模型)时,可以直接让 Net-S 去学习 Net-T 的泛化能力。
一个直白高效的迁移泛化能力的方法就是:使用 softmax 层输出的类别的概率来作为「soft target」
通用的知识蒸馏方法
- 第一步是训练 Net-T
- 第二步是在高温 T 下,蒸馏 Net-T 的知识到 Net-S
蒸馏过程的目标函数由 distill loss(对应 soft target)和 student loss(对应 hard target)加权得到