强化学习
强化学习
强化学习目标:找到一个策略去最大化 奖励
即 训练一个 Policy 神经网络 ,在所有的 Trajectory(状态动作序列) 中,得到 Return(reward 总和)的期望最大
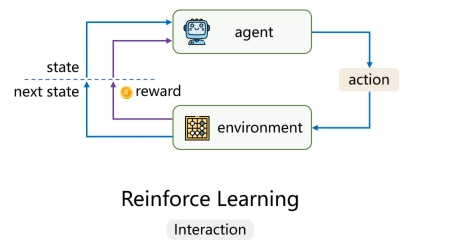
MDP(Markov Decision Process,马尔科夫决策)
Action、State、Reward 的执行轨迹(Trajectory )

t 时刻 回报 Return:
更 复杂 的情况:
- 状态 s 可以采取多个 a
- 状态采取多个 a 后可能会进入多个不同的 s’
因此:
- :当前状态 s 采取动作 a 的概率分布
- :当前状态 s 采取动作 a 后进入状态 s’ 的概率分布
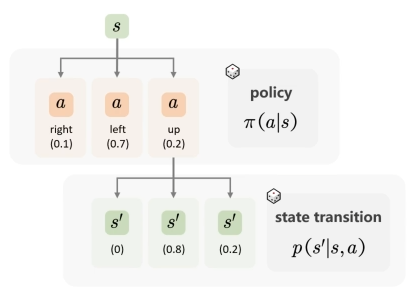
此时可以分别计算 State Value(状态价值) 和 Action Value(动作价值)
State Value(状态价值)的期望函数:
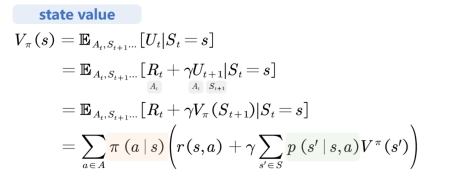
Action Value(动作价值)的期望函数:
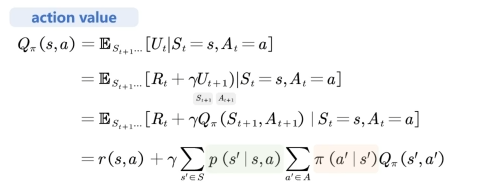
状态价值 和 动作价值 的关系:
强化学习分类
强化学习方法可以分为 以获得「最大奖励」为基础的 value-based 方法 和 通过预测动作可以获得最大奖励的「概率分布」的 policy-based 方法
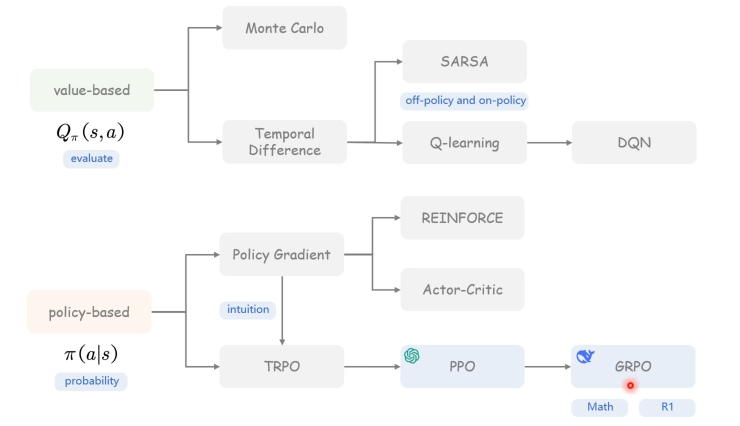
Value-Based 方法
Monte Carlo 蒙特卡洛
目标:估计 的最大值
问题:需要走完一次流程(玩完一局)
Temporal Difference 时序差分
目标:估计 的最大值
优势:可以通过已经经历过的 真实值 按 步 更新 ,减少误差
SARSA
SARSA 即 state-action-reward-state-actioin
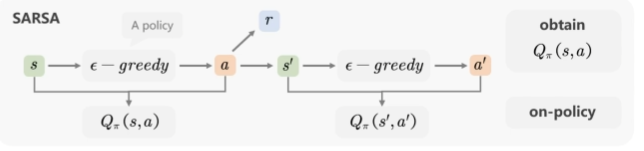
- 通过 选择点前状态的最优动作,类似查表,但允许一定的探索
Q-learning
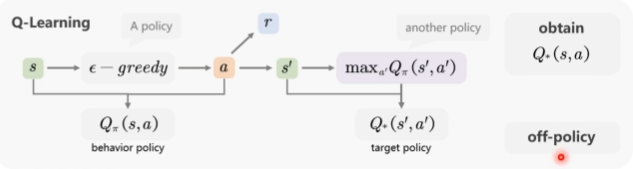
- Q-learning 在第二步(下一步)时直接选择最大的 动作-状态-价值(类似直接查表拿最大)
价值更新
有了 第一步 和 第二步 的 状态-动作-价值 后,就可以对 价值 进行更新
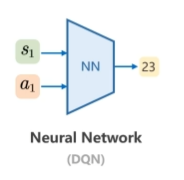
更新方式有 Table Update 或 NN Update 两种方式
- Table Update:
- NN Update:
行为策略: 获得当前步的 方式为行为策略(与环境互动、产生数据的策略)
目标策略:获得下一步的 方式为目标策略(评估或优化的那个策略)
on-policy:行为策略与目标策略相同
off-policy:行为策略与目标策略不同
Policy-Based 方法
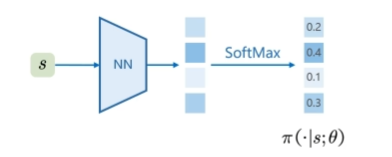
Poliocy Gradient 策略梯度
我们期望状态价值是最大的
因此我们需要
我们采取 梯度上升:,其中 为学习率, 为梯度
公式对推导:
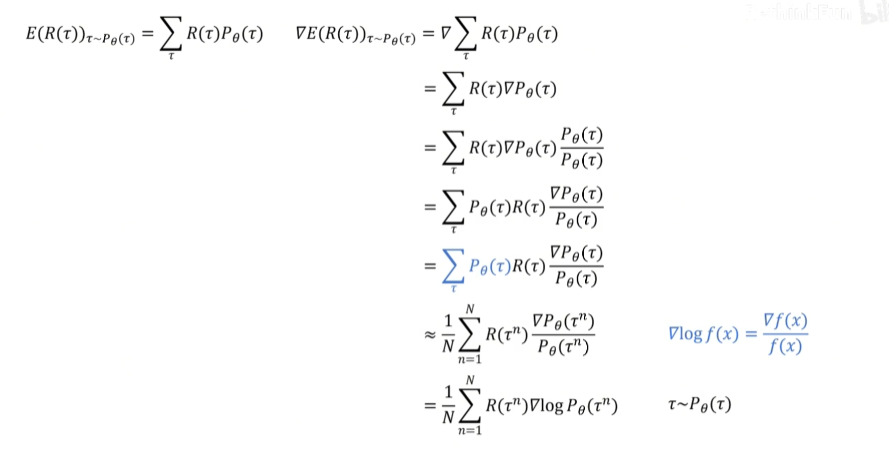
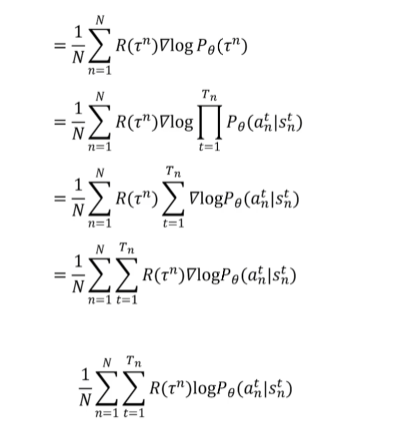
TRPO(Trust Region Policy Optimization)
Poliocy Gradient 的问题在于学习率难以设定,因此我们需要约束这个梯度在一个小范围中

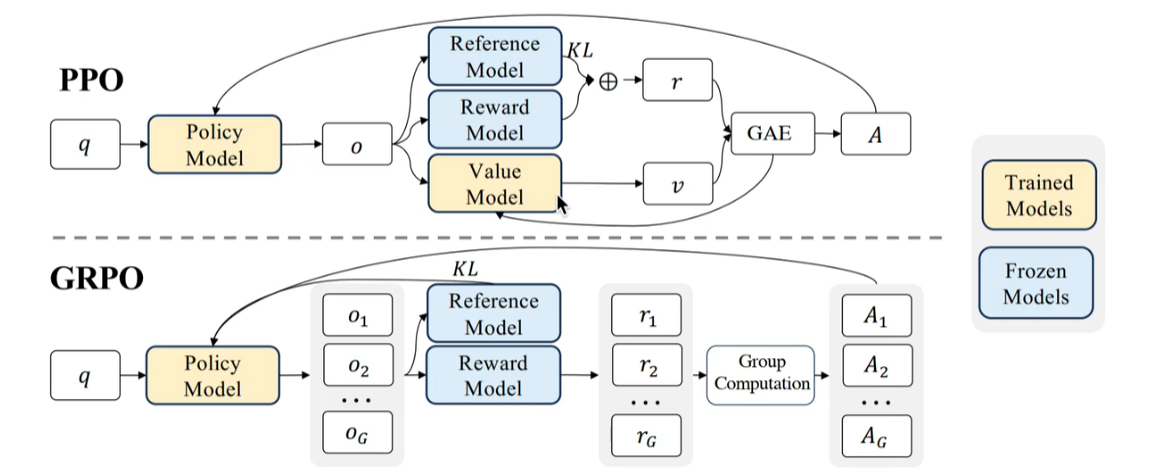
PPO(Proximal Policy Optimization 邻近策略优化)
on-policy 和 off-policy 的特性:
- on-policy:训练数据有当前策略产生,数据用完就丢
- off-policy:数据来源可以是历史策略、探索策略、甚至人类专家
如何将 on-policy 的训练替换成 off-policy 的训练?
重要性采样
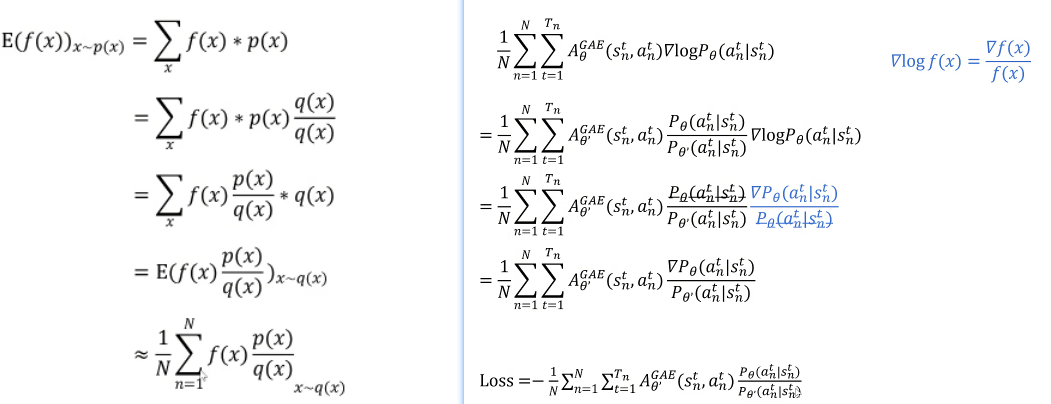
由于参考策略和训练的策略在概率分布上不能相差过大,因此引入「KL 散度」 ****
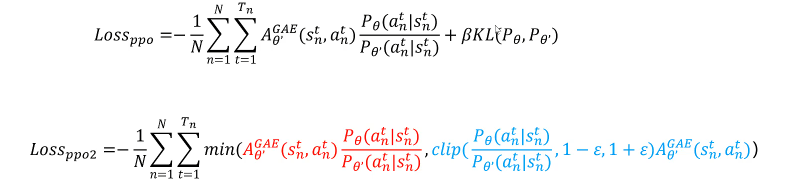
GRPO