并行/分布式 DP/TP/PP/EP
并行/分布式 DP/TP/PP/EP
现有问题:
- 单卡 GPU 显存有限,分为两个维度
- 数据维度:对于小模型而言,单卡能放下一个模型,但没法放下一个 batch 所要的全部数据,因此数据得切分到不同卡上计算最终汇总,从而引入数据并行 DP
- 模型维度:对于大模型而言,单卡无法放下一个模型,必须将模型切分到多张卡上,因此引入了除 DP 之外的各种并行(TP/PP/EP/SP),可统称为模型并行
DP/TP/PP/EP/SP 都可以同时开启(EP 依赖于 DP,只有 DP 开启的情况下,才可能开启 EP;SP 依赖于 TP,只有在 TP 开启的情况下才能用 SP)
数据并行 (Data Parallelism)
DP:每张卡拷贝 相同 的 模型结构,仅对 数据 做 切分。每张卡计算完的 梯度 也是针对 各自数据 的,需要做一次 allreduce,然后使用优化器更新模型,进入下一次迭代。
DP 在所有并行中 效率最高。 除了一次 allreduce 之外,没有任何额外通信开销,其通信量为 。M 是模型大小,dtype 是数据类型,2 是因为 allreduce 的特性
DP 的缺点是:只能放 微小模型。以 llama-7B 的 bf16 混合训练为例,显存占用至少是 ,其中模型和梯度各占 2byte,adam 优化器占 12byte。
DP 为所有并行中 首选 且必带的。同时只要一张卡放不下一个 batch 中的数据(以及其产生的激活值),DP 也是必选的
张量并行(Tensor Parallelism)
TP 能分摊模型到多张卡上,但带来了不小的通信开销,影响训练效率
TP 允许对模型 内部 的参数矩阵切分(一层切开),然后利用分块矩阵乘进行计算得到正确结果,由于参数矩阵是以 tensor 表示,故叫 张量并行
TP 因为通信量太大了,只有单机内 nvlink 这种高带宽才能支持(H100 900GB/s 卡间通信),一旦跨机即便是 IB(InfiniBand 无限带宽技术) 也不够。
张量并行带来的额外通信开销是 。 是 batch, 是 seqlen, 是 hidden_size, 是模型的层数
流水线并行(Pipeline Parallelism)
由于 TP 通信量很大。PP 则是按 layer 进行切分(例如一个模型是 8 层,切分到 2 张卡上,每一张卡放 4 层)。单卡通信量仅为
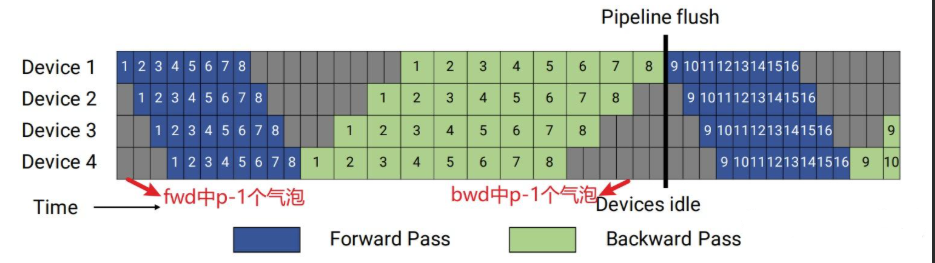
常规的 pp 会带来一个严重的问题,那就是气泡率(算力闲置与浪费现象)较高
- 前向传播时: 位于下游的 GPU 1 必须等待上游的 GPU 0 算完 1-4 层并把激活值传过来,才能开始计算 5-8 层。在这个漫长的等待期里,GPU 1 是完全空闲的。
- 反向传播时: 顺序反过来了。上游的 GPU 0 必须等待下游的 GPU 1 算完误差梯度并传回来,才能开始更新自己负责的 1-4 层。此时,轮到 GPU 0 闲置了。
解决方式:
- Micro-batching(微批次,如 GPipe 算法):把大 Batch 拆分成多个极小的 Micro-batch。GPU 0 算完第 1 个 Micro-batch,立刻通过网络发给 GPU 1;然后 GPU 0 不停歇,紧接着算第 2 个 Micro-batch。这样,流水线就能迅速“流动”起来,下游 GPU 的等待时间被大幅压缩,气泡占比显著降低。
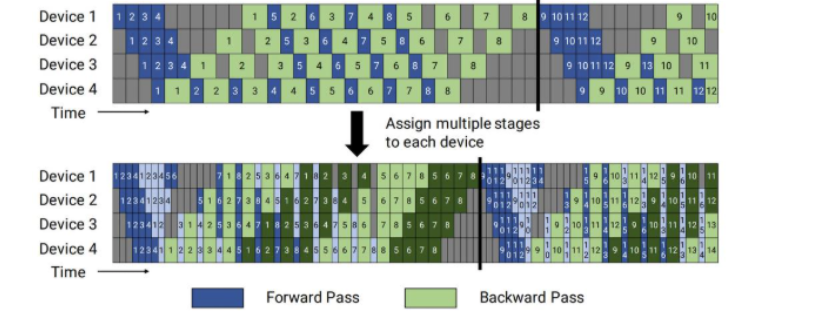
- 1F1B 调度(One Forward One Backward):虽然 GPipe 减小了气泡,但它要求 GPU 缓存所有 Micro-batch 的前向激活值,直到最后才统一做反向传播,这会导致显存瞬间被撑爆(OOM)。
为了解决这个问题我们让 GPU 尽量做到“执行一次前向传播后,立刻执行一次反向传播”,算完立刻释放这部分激活值的显存。
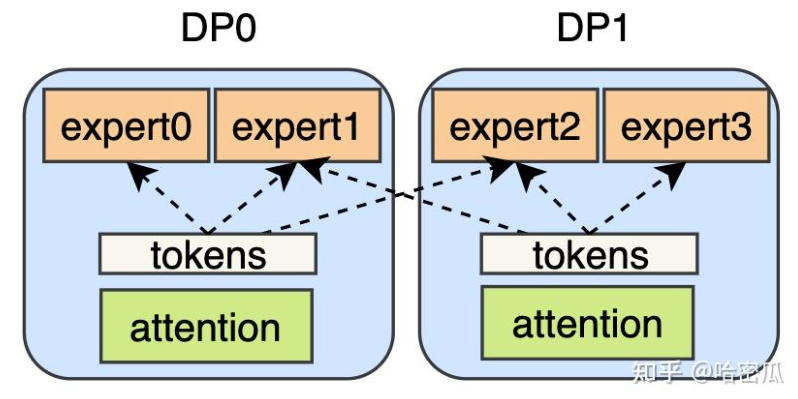
专家并行(Expert Parallelism)
专家并行主要解决的是 MoE 模型的问题,moe 模型结构如下图:
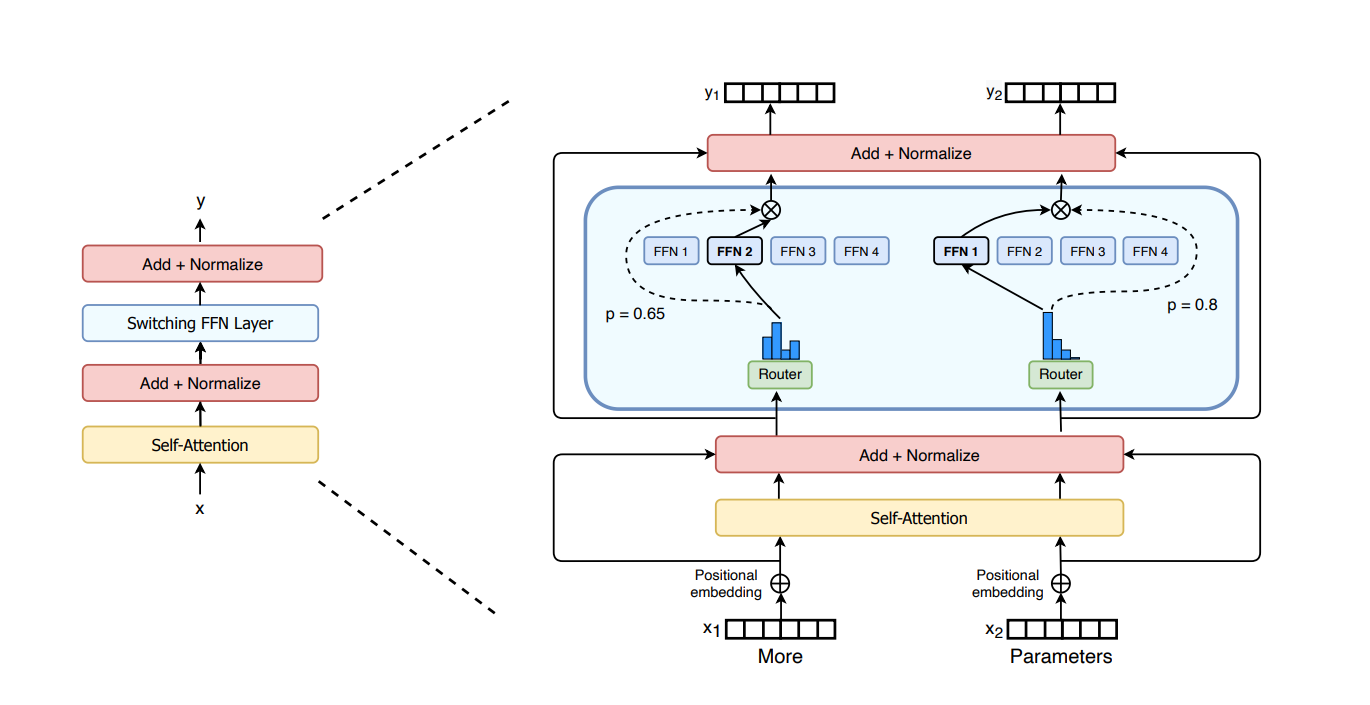
由于每个 token 只会分发给 topk 个专家,导致每个专家(FFN)只处理一部分 token,计算效率很低(一次处理的 token 减少)。
为了提升计算效率,会将专家分摊在不同的 DP(不同 GPU) 上。在之前的各种并行中,每个 DP 拥有完整的模型,在 FWD 和 BWD 时也是各自处理各自的数据,不会有任何通信(只会在梯度 allreduce 时涉及 DP 间通信)。而在 EP 中,专家被分摊到不同的 DP 里面,在前向和反向时 DP 之间便会有数据的通信
一般会通过 all2all 进行数据的分发,同时并行组也会复杂不少