Word2Vec
2026/4/17大约 1 分钟
Word2Vec
Word2Vec 的设计理念源自 **分布假设** ——即一个词的含义由它周围的词决定
Word2Vec 提供了两种典型的模型结构,用于实现对词向量的学习:
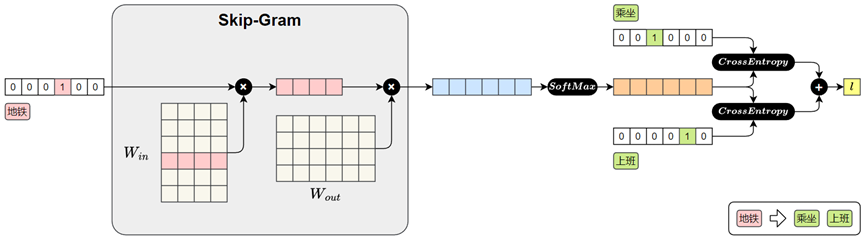
- Skip-gram 模型
- 输入是一个中心词,模型的目标是预测其上下文中的所有词(即前后若干个词)、
- 输入词用 one-hot 向量表示
- 与参数矩阵 相乘,取出“地铁”对应的词向量
- 将中心词向量与参数矩阵 相乘,得到对整个词表的预测得分
- 得分通过 Softmax 转为概率分布,表示各词作为上下文的可能性
- 与真实上下文词“乘坐”、“上班”进行比对,计算交叉熵损失并求和,得到总损失
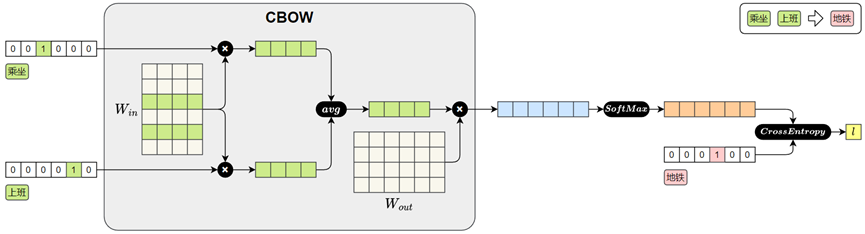
- CBOW 模型
- 输入是一个词的上下文(即前后若干个词),模型的目标是预测中间的目标词只要按照上述目标训练模型,就能得到语义化的词向量
- 输入词用 one-hot 向量表示,得到对应词向量
- 将多个上下文词向量取平均,得到一个整体的上下文表示
- 将平均后的上下文向量与参数矩阵 相乘,得到对整个词表的预测得分
- 将得分输入Softmax,得到每个词作为中心词的概率分布
- 将预测结果与真实中心词“地铁”的one-hot向量进行比对,计算交叉熵损失